双重水印
概要
现有借助深度学习添加水印的模型,大多无法抵御 双重水印攻击,即 若想破坏某模型的在某图像上的水印,只需再使用该模型在该图像上添加一次水印。为抵御该攻击,首先应思考,模型二次对图像编码时:
- 输出图像应与原图有何差异?
- 第一次嵌入的信息应如何变化?。
一种合理的情况是:1)输出图像应与原图应尽可能相同;2)第一次嵌入的信息应仍然保留。
实验记录
SepMark
【失败实验一】也许是权重设置错误
失败原因:
原先并未想到 概要 中那一层次,而是:
- 输出图像应尽可能与原图像相同
- 第一次嵌入的信息应仍然保留
实验设置:
- 全量微调
- 包括噪音层
- 微调共 21 轮
实验结果:
其实已经达到预先设想的目标,但可惜在测试时发现双重编码会使得 PNSR 显著下降,即使在代码中添加了对其不许下降的约束。这进而促使我思考 输出的图像是否应与原图保持相同。
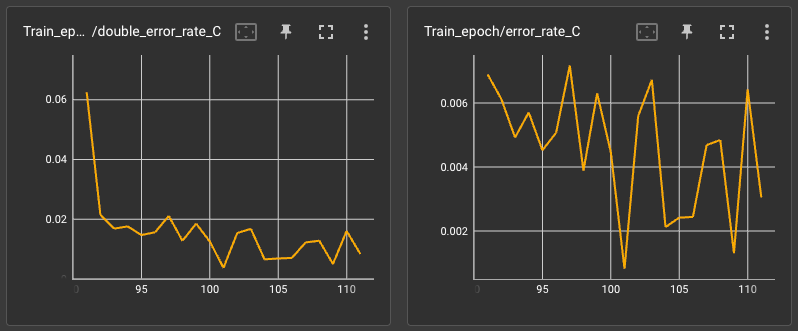
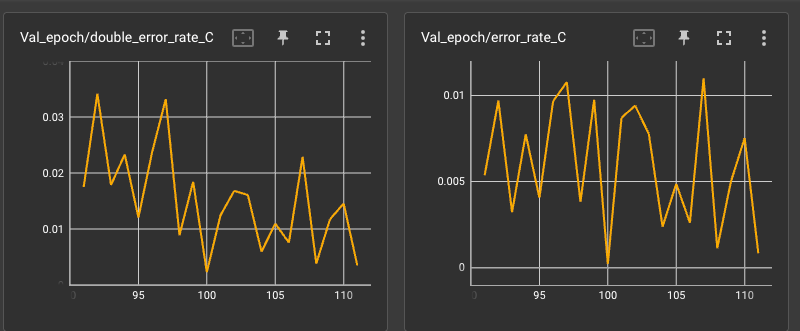
值得一提的是,对损失加入了 余弦退火 scheduler 才得到如此效果(未加入时,双解码错误率始终在 5% ~ 10% 波动,后期训练甚至越来越高)。
实验后第 110 轮模型水印添加图:

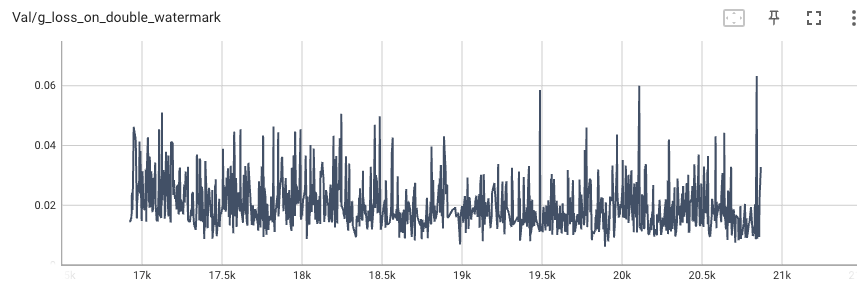
在验证集上双水印损失完全没有下降。
【失败实验二】测试编码器、解码器微调
失败原因:
此时仍未想到 概要 中那一层,且希望通过:
- 单独 微调解码器,达到【失败实验一】中的期望。
- 或 单独 微调编码器,达到【失败实验一】中的期望。
实验设置:
- 单独微调解码器或单独微调编码器
- 包括噪音层
- 微调共 10 轮
实验结果:
单独微调解码器或编码器,都未能使得双解码错误率下降到较为合适的范围($\leq 1\%$)
【实验三】黑图生成(也许是错误方向)
实验设置:
- 全量微调
- 约束设置为:1)限制二次编码输出图像为黑图;2)限制二次编码输出图像仍包含一次编码水印信息。仍使用 SepMark 进行实验,实验的二次编码水印 Loss 如下:
1
2
3
4
5
6
g_loss_on_double_watermark = (
self.criterion_MSE(double_encoded_images, torch.zeros_like(images))*0.01 +
self.criterion_MSE(double_decoded_messages_C, messages)*5 +
self.criterion_MSE(double_decoded_messages_R, messages) +
self.criterion_MSE(double_decoded_messages_F, torch.zeros_like(messages))
)
- 使用余弦退火:
num_warmup_steps=len(train_dataloader)*0.1, num_training_steps=len(train_dataloader)*5
【失败实验四】残差差异最小化全量微调
实验设置:
1
2
3
4
5
6
7
8
9
double_message = torch.Tensor(np.random.choice([-self.message_range, self.message_range], (images.shape[0], self.message_length))).to('cuda')
double_encoded_images, double_noised_images, double_decoded_messages_C, double_decoded_messages_R, double_decoded_messages_F = self.encoder_decoder(noised_images, double_message, masks)
g_loss_on_double_watermark = (
self.criterion_MSE(double_encoded_images-images, encoded_images-images) +
# self.criterion_MSE(double_encoded_images, images) +
self.criterion_MSE(double_decoded_messages_C, messages) +
self.criterion_MSE(double_decoded_messages_R, messages)*0.1 +
self.criterion_MSE(double_decoded_messages_F, torch.zeros_like(messages)*0.1)
)
感觉自己 sb 了,二次编码残差不是应该全为 0 才是最好的吗?有些时候明明是很简单的问题。
【失败实验五】二次残差归零
1
2
3
4
5
6
7
8
double_message = torch.Tensor(np.random.choice([-self.message_range, self.message_range], (images.shape[0], self.message_length))).to('cuda')
double_encoded_images, double_noised_images, double_decoded_messages_C, double_decoded_messages_R, double_decoded_messages_F = self.encoder_decoder(noised_images, double_message, masks)
g_loss_on_double_watermark = (
self.criterion_MSE(double_encoded_images-encoded_images, torch.zeros_like(double_encoded_images)) +
self.criterion_MSE(double_decoded_messages_C, messages) +
self.criterion_MSE(double_decoded_messages_R, messages)*0.1 +
self.criterion_MSE(double_decoded_messages_F, torch.zeros_like(messages)*0.1)
)
HiDDeN
【实验一】黑图生成
水印损失设置如下:
1
2
3
4
5
6
7
# ========================= Double watermarking ========================= #
double_message = torch.Tensor(np.random.choice([0, 1], (images.shape[0], self.config.message_length))).to(self.device)
double_encoded_images, double_noised_images, double_decoded_messages = self.encoder_decoder(noised_images, double_message)
g_loss_double = (
self.mse_loss(double_decoded_messages, messages) * self.double_message_weight +
self.mse_loss(double_encoded_images, torch.zeros_like(encoded_images)) * self.double_black_image_weight
)
已先按照作者原来的设置,在没有噪音层的情况下跑了 200 个 epoch,得到了效果比较好的模型。把该模型作为预训练的模型,微调 100 个 epoch 之后,出现了和当时测试 MBRS 一样的情况(以下每一点都与测试 MBRS 时相同):
- 训练 显示解码误差、双解码误差都小($BER<5\%$);
- 验证、测试 显示解码误差、双解码误差都大($BER>20\%$);
- 测试 时,把测试集更换为训练集的部分图片,显示解码误差、双解码误差都大($BER>20\%$)
- 测试 时,把测试模型改为没有微调的,显示解码误差小($BER<1\%$)、双解码误差大($BER>20\%$)
调试了半天之后,发现只要设置 self.network.encoder_decoder.eval() 之后,错误率就会非常高。问了 GPT 之后,确定是问题是 BatchNorm 统计量未正确更新。
!!! tip “BatchNorm 统计量未正确更新” 现象
1
2
3
4
5
在训练阶段,BatchNorm层使用当前批次的均值和方差进行归一化,并逐步更新其running_mean和running_var(指数滑动平均)。但在eval()模式下,BatchNorm会固定使用训练阶段累积的全局统计量。
**问题根源**
如果在训练过程中没有正确调用train()模式,BatchNorm的running_mean和running_var可能未被更新(例如,训练时模型意外处于eval()模式)。这会导致评估时使用错误(或初始随机值)的统计量,模型表现骤降。
不论是 HiDDeN 还是 MBRS,在评估时注释掉 self.network.encoder_decoder.eval() 之后结果便恢复正常。
!!! tip “根本原因” BN 的统计量更新机制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
训练阶段:BN 层基于 **每个批次** 的均值和方差(当前批统计量)对输入进行归一化,并通过指数移动平均(EMA)更新全局统计量 running_mean 和 running_var;评估阶段:BN 层使用 **训练阶段累积的全局统计量**,而非当前批的统计量。
**两次前向传播的问题**
*经过各种修改和测试,问题并未解决,或许不是这些原因,但是也找不到原因,就先按这些原因记录吧。*
```python
# 第一次前向传播(基于原始数据)
encoded_images, noised_images, decoded_messages = self.encoder_decoder(images, messages)
# 第二次前向传播(基于噪声数据)
double_encoded_images, _, double_decoded_messages = self.encoder_decoder(noised_images, double_message)
```
第一次前向传播:使用原始数据 images,BN 层计算当前批的均值和方差,更新全局统计量。第二次前向传播:使用噪声数据 noised_images,BN 层再次计算当前批的均值和方差,并基于此更新全局统计量。
如果 noised_images 的分布与原始 images 差异较大(例如添加了强噪声),第二次前向传播会基于噪声数据更新全局统计量,导致 running_mean 和 running_var 偏离原始数据分布。在评估模式下,模型使用被污染的全局统计量进行归一化,导致性能显著下降。
我想到的第一个办法是,每次 train_step 只做一次前向传播,但 train_step 会按照交替顺序,接受原图、编码图(上一次原图的编码图)。这其实也就是在遍历 batch 的那一层循环中,设置两个 train_step,第一个 train_step 接受原图,第二个 train_step 接受上一次原图的编码图。但这个办法的问题是,a) 没有改 Loss,而且好像就没有改什么东西,那写创新点就不好写了;b) 这样问题不一定能解决,还是前向传播了两次,BN 层统计量还是更新了两次,和原来有什么区别吗?其实问题 b) 倒也还是其次,最重要的是问题 a),这样即使做出来意义也不大。
折中的办法是测试的时候不要 eval。
多次编码时效果不好,原水印会被破坏。
实验结果
从上到下依次为:原图、一次编码图、一次编码图和原图残差、双编码图、双编码图和原图残差

| bitwise-error | d_bitwise-error | name | multi_encoding_num |
|---|---|---|---|
| 0.021142 | 0.495679 | origin | 1 |
| 0.00756173 | 0.0126543 | multi | 1 |
| 0.0137346 | 0.507562 | origin | 2 |
| 0.0137346 | 0.0484568 | multi | 2 |
| 0.0111111 | 0.499383 | origin | 3 |
| 0.0146605 | 0.21034 | multi | 3 |
MBRS
【实验一】黑图生成
水印损失设置如下:
1
2
3
4
5
6
7
# ======================= Double watermarking ====================== #
double_message = torch.Tensor(np.random.choice([0, 1], (images.shape[0], self.message_length))).to(self.device)
double_encoded_images, _, double_decoded_messages = self.encoder_decoder(noised_images, double_message)
g_loss_on_double_watermark = (
self.criterion_MSE(double_encoded_images, torch.zeros_like(images)) * self.double_output_black_image_weight +
self.criterion_MSE(double_decoded_messages, messages) * self.double_decoded_message_weight
)
出现以下情况(同 HiDDeN):
- 训练 显示解码误差、双解码误差都小($BER<5\%$);
- 验证、测试 显示解码误差、双解码误差都大($BER>20\%$);
- 测试 时,把测试集更换为训练集的部分图片,显示解码误差、双解码误差都大($BER>20\%$)
- 测试 时,把测试模型改为没有微调的,显示解码误差小($BER<1\%$)、双解码误差大($BER>20\%$)
- 训练 时,把验证集换为训练集,显示验证解码误差、双解码误差都大($BER>20\%$),而训练解码误差、双解码误差都小($BER<5\%$)
只能取折中的办法,即测试的时候不要 eval。但即使这样,MBRS 还是会出现一定的精度损失(别的模型没有类似情况)。
StegaStamp
备注(实验时的突发奇想,有些后经验证无法实现,或并不合理)
- 【合理】AdvMark 并没有验证其方法对于模型的普遍性,只是验证了检测器的流通性。
- 【无法实现】冻结 encoder,只微调 decoder,这样就可以测试不同水印模型之间的流通性。
- 【合理】用非入侵式的方法来增加微调模块。新建一个 fine_tuning 文件夹,用继承的方式修改需要重写的方法。尽量把所有的东西都放到该 fine_tuning 文件夹中(除了跑通原模型所必要的数据集之类的)。这里需要注意 Python 包导入的问题,在 fine_tuning 文件夹中导入原模型的包因使用绝对导入,导入 fine_tuning 文件夹的内容则使用直接导入
- 弄清楚 & 小汇报:
- 前景提示:提出一种微调任意使用深度学习的水印模型的方法,使二次水印注入攻击失效
- 小汇报:
- 刚开始设计的损失:a)原图和二次编码的图像差异应该很小;b)二次编码后的图像水印信息不能丢失。
- 用此损失函数训练好之后,效果(指二次编码错误率)很好,但发现忘记加噪音层。
- 加噪音层之后,训练效果不太好,调了段时间的超参,发现用 余弦退火 效果好了
- 训练好之后,我写了测试代码来生成编码一次、两次、三次等后,图像的水印留存率。结果发现越编码图像质量稍微再下降
- 突然发现,二次编码应算一个恶意操作,该直接在二次编码后生成一张扭曲图像,以警示使用者不能对图像二次编码。同时保留水印,以防扭曲图像操作失效。
- 但由于扭曲图像和一次编码图像使用的都是同一个 encoder,应该在保证一次编码图像质量的情况下,降低二次编码图像质量,即扭曲图像对应损失权重应该远小于二次编码图像质量的权重
- 弄清楚
- 上述思路是否存在问题
- 损失设计中,我想破坏图像,是不是应该看一些对抗的论文
- 闲话
- 跑实验没事看看论文,现在发现确实看论文快多了,开学前还是得需要两个小时,现在一个小时之内就行了